# Usar EXPLAIN e EXPLAIN ANALYZE no Athena
A instrução `EXPLAIN` mostra o plano de execução lógico ou distribuído de uma instrução SQL especificada ou valida a instrução SQL. Você pode gerar os resultados no formato de texto ou em um formato de dados para renderização em gráfico.
**nota**
É possível visualizar representações gráficas de planos lógicos e distribuídos para suas consultas no console do Athena sem usar a sintaxe `EXPLAIN`. Para obter mais informações, consulte [Visualização de planos de execução para consultas SQL](query-plans.md).
O `EXPLAIN ANALYZE` mostra o plano de execução distribuído de uma instrução SQL especificada e o custo computacional de cada operação em uma consulta SQL. Você pode gerar os resultados no formato de texto ou JSON.
## Considerações e limitações
As instruções `EXPLAIN` e `EXPLAIN ANALYZE` no Athena têm as limitações a seguir.
+ Como as consultas `EXPLAIN` não verificam os dados, o Athena não cobra por elas. Entretanto, como as consultas `EXPLAIN` fazem chamadas ao AWS Glue para recuperar metadados de tabela, poderá haver cobranças do Glue se as chamadas ultrapassarem o [limite do nível gratuito do Glue](https://aws.amazon.com/free/?all-free-tier.sort-by=item.additionalFields.SortRank&all-free-tier.sort-order=asc&awsf.Free%20Tier%20Categories=categories%23analytics&all-free-tier.q=glue&all-free-tier.q_operator=AND).
+ Como consultas `EXPLAIN ANALYZE` são executadas, elas verificam os dados, e o Athena cobra pela quantidade de dados verificados.
+ As informações de filtragem de linha ou de célula definidas no Lake Formation e as informações de estatísticas de consulta não são mostradas na saída de `EXPLAIN` e de `EXPLAIN ANALYZE`.
## Sintaxe de EXPLAIN
```
EXPLAIN [ ( {{option}} [, ...]) ] {{statement}}
```
{{opção}} pode ser uma das seguintes:
```
FORMAT { TEXT | GRAPHVIZ | JSON }
TYPE { LOGICAL | DISTRIBUTED | VALIDATE | IO }
```
Se a opção `FORMAT` não for especificada, o padrão de saída será o formato `TEXT`. O tipo`IO` fornece informações sobre as tabelas e os esquemas lidos pela consulta.
## Sintaxe de EXPLAIN ANALYZE
Além da saída incluída em `EXPLAIN`, a saída de `EXPLAIN ANALYZE` também inclui estatísticas de runtime para a consulta especificada, como o uso da CPU, o número de linhas da entrada e o número de linhas da saída.
```
EXPLAIN ANALYZE [ ( {{option}} [, ...]) ] {{statement}}
```
{{opção}} pode ser uma das seguintes:
```
FORMAT { TEXT | JSON }
```
Se a opção `FORMAT` não for especificada, o padrão de saída será o formato `TEXT`. Porque todas as consultas para `EXPLAIN ANALYZE` são `DISTRIBUTED`, a opção `TYPE` não está disponível para `EXPLAIN ANALYZE`.
A {{instrução}} pode ser uma das seguintes:
```
SELECT
CREATE TABLE AS SELECT
INSERT
UNLOAD
```
## Exemplos de EXPLAIN
Os exemplos a seguir representam a progressão de `EXPLAIN`, do mais simples ao mais complexo.
### Exemplo 1: uso da a instrução EXPLAIN para mostrar um plano de consulta no formato de texto
No exemplo a seguir, `EXPLAIN` mostra o plano de execução de uma consulta `SELECT` nos logs do Elastic Load Balancing. O formato é o padrão para saída de texto.
```
EXPLAIN
SELECT
request_timestamp,
elb_name,
request_ip
FROM sampledb.elb_logs;
```
#### Resultados
```
- Output[request_timestamp, elb_name, request_ip] => [[request_timestamp, elb_name, request_ip]]
- RemoteExchange[GATHER] => [[request_timestamp, elb_name, request_ip]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=sampledb, tableName=elb_logs,
analyzePartitionValues=Optional.empty}] => [[request_timestamp, elb_name, request_ip]]
LAYOUT: sampledb.elb_logs
request_ip := request_ip:string:2:REGULAR
request_timestamp := request_timestamp:string:0:REGULAR
elb_name := elb_name:string:1:REGULAR
```
### Exemplo 2: uso de EXPLAIN para representar um plano de consulta graficamente
É possível utilizar o console do Athena para representar um plano de consulta graficamente para você. Insira uma instrução `SELECT` como a seguinte no editor de consultas do Athena e escolha **EXPLAIN**.
```
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
```
A página **Explain** (Explicar) do editor de consultas do Athena é aberta e mostra um plano distribuído e um plano lógico para a consulta. O gráfico a seguir mostra o plano lógico do exemplo.
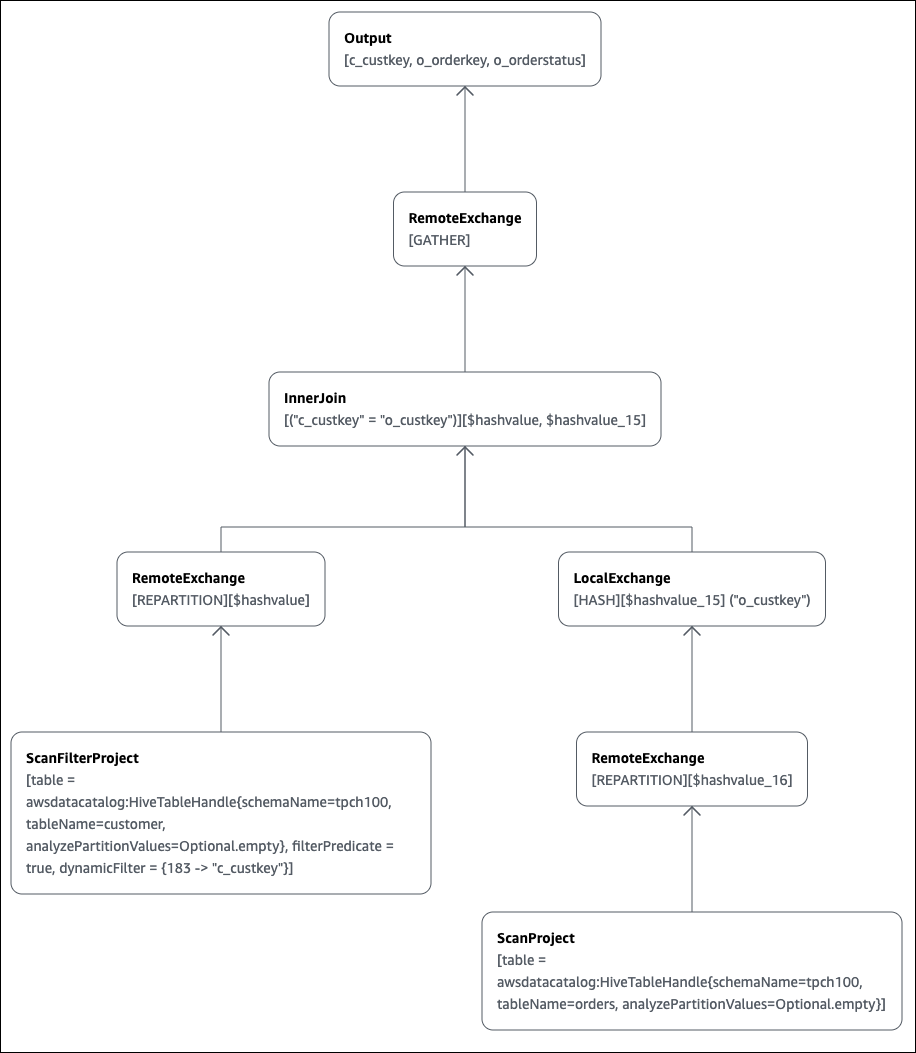
**Importante**
Alguns filtros de partição podem não estar visíveis no gráfico de árvore do operador aninhado, mesmo que o Athena os aplique à sua consulta. Para verificar o efeito desses filtros, execute `EXPLAIN` ou `EXPLAIN ANALYZE` na sua consulta e visualize os resultados.
Para obter mais informações sobre como usar os recursos de gráfico do plano de consulta no console do Athena, consulte [Visualização de planos de execução para consultas SQL](query-plans.md).
### Exemplo 3: uso da instrução EXPLAIN para verificar redução da partição
Quando você usa um predicado de filtragem em uma chave particionada para consultar uma tabela particionada, o mecanismo de consulta aplica o predicado à chave particionada para reduzir a quantidade de dados lidos.
O exemplo a seguir usa uma consulta `EXPLAIN` para verificar a remoção da partição de uma consulta `SELECT` em uma tabela particionada. Primeiro, a instrução `CREATE TABLE` cria a tabela `tpch100.orders_partitioned`. A tabela é particionada na coluna `o_orderdate`.
```
CREATE TABLE `tpch100.orders_partitioned`(
`o_orderkey` int,
`o_custkey` int,
`o_orderstatus` string,
`o_totalprice` double,
`o_orderpriority` string,
`o_clerk` string,
`o_shippriority` int,
`o_comment` string)
PARTITIONED BY (
`o_orderdate` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION
's3://amzn-s3-demo-bucket/{{}}/'
```
A tabela `tpch100.orders_partitioned` tem várias partições em `o_orderdate`, como mostrado pelo comando `SHOW PARTITIONS`.
```
SHOW PARTITIONS tpch100.orders_partitioned;
o_orderdate=1994
o_orderdate=2015
o_orderdate=1998
o_orderdate=1995
o_orderdate=1993
o_orderdate=1997
o_orderdate=1992
o_orderdate=1996
```
A consulta `EXPLAIN` a seguir verifica a remoção da partição com base na instrução `SELECT` especificada.
```
EXPLAIN
SELECT
o_orderkey,
o_custkey,
o_orderdate
FROM tpch100.orders_partitioned
WHERE o_orderdate = '1995'
```
#### Resultados
```
Query Plan
- Output[o_orderkey, o_custkey, o_orderdate] => [[o_orderkey, o_custkey, o_orderdate]]
- RemoteExchange[GATHER] => [[o_orderkey, o_custkey, o_orderdate]]
- TableScan[awsdatacatalog:HiveTableHandle{schemaName=tpch100, tableName=orders_partitioned,
analyzePartitionValues=Optional.empty}] => [[o_orderkey, o_custkey, o_orderdate]]
LAYOUT: tpch100.orders_partitioned
o_orderdate := o_orderdate:string:-1:PARTITION_KEY
:: [[1995]]
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR
```
O texto em negrito no resultado mostra que o predicado `o_orderdate = '1995'` foi aplicado a `PARTITION_KEY`.
### Exemplo 4: uso de uma consulta EXPLAIN para verificar ordem e tipo de junção
A consulta `EXPLAIN` a seguir verifica o tipo e a ordem de junção da instrução `SELECT`. Use uma consulta como esta para examinar o uso da memória de consulta para que você possa reduzir as chances de receber um erro `EXCEEDED_LOCAL_MEMORY_LIMIT`.
```
EXPLAIN (TYPE DISTRIBUTED)
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.customer c
JOIN tpch100.orders o
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123
```
#### Resultados
```
Query Plan
Fragment 0 [SINGLE]
Output layout: [c_custkey, o_orderkey, o_orderstatus]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- Output[c_custkey, o_orderkey, o_orderstatus] => [[c_custkey, o_orderkey, o_orderstatus]]
- RemoteSource[1] => [[c_custkey, o_orderstatus, o_orderkey]]
Fragment 1 [SOURCE]
Output layout: [c_custkey, o_orderstatus, o_orderkey]
Output partitioning: SINGLE []
Stage Execution Strategy: UNGROUPED_EXECUTION
- CrossJoin => [[c_custkey, o_orderstatus, o_orderkey]]
Distribution: REPLICATED
- ScanFilter[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("c_custkey" = 123)] => [[c_custkey]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
- LocalExchange[SINGLE] () => [[o_orderstatus, o_orderkey]]
- RemoteSource[2] => [[o_orderstatus, o_orderkey]]
Fragment 2 [SOURCE]
Output layout: [o_orderstatus, o_orderkey]
Output partitioning: BROADCAST []
Stage Execution Strategy: UNGROUPED_EXECUTION
- ScanFilterProject[table = awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=orders, analyzePartitionValues=Optional.empty}, grouped = false,
filterPredicate = ("o_custkey" = 123)] => [[o_orderstatus, o_orderkey]]
LAYOUT: tpch100.orders
o_orderstatus := o_orderstatus:string:2:REGULAR
o_custkey := o_custkey:int:1:REGULAR
o_orderkey := o_orderkey:int:0:REGULAR
```
A consulta de exemplo foi otimizada em uma junção cruzada para uma performance melhor. Os resultados mostram que `tpch100.orders` será distribuído como o tipo de distribuição `BROADCAST`. Isso indica que a tabela `tpch100.orders` será distribuída para todos os nós que executam a operação de junção. O tipo de distribuição `BROADCAST` exige que todos os resultados filtrados da tabela `tpch100.orders` estejam dentro da capacidade de memória de cada nó que executa a operação de junção.
No entanto, a tabela `tpch100.customer` é menor que `tpch100.orders`. Como `tpch100.customer` requer menos memória, você pode reescrever a consulta como `BROADCAST tpch100.customer` em vez de `tpch100.orders`. Desse modo, a consulta tem menos chance de receber o erro `EXCEEDED_LOCAL_MEMORY_LIMIT`. Essa estratégia considera os seguintes pontos:
+ `tpch100.customer.c_custkey` é exclusivo na tabela `tpch100.customer`.
+ Existe um relacionamento de mapeamento um para muitos entre `tpch100.customer` e `tpch100.orders`.
O exemplo a seguir mostra a consulta reescrita.
```
SELECT
c.c_custkey,
o.o_orderkey,
o.o_orderstatus
FROM tpch100.orders o
JOIN tpch100.customer c -- the filtered results of tpch100.customer are distributed to all nodes.
ON c.c_custkey = o.o_custkey
WHERE c.c_custkey = 123
```
### Exemplo 5: uso de uma consulta EXPLAIN para remover predicados sem efeito
Você pode usar uma consulta `EXPLAIN` para verificar a eficácia dos predicados de filtragem. Você pode usar os resultados para remover os predicados que não têm efeito, como no exemplo a seguir.
```
EXPLAIN
SELECT
c.c_name
FROM tpch100.customer c
WHERE c.c_custkey = CAST(RANDOM() * 1000 AS INT)
AND c.c_custkey BETWEEN 1000 AND 2000
AND c.c_custkey = 1500
```
#### Resultados
```
Query Plan
- Output[c_name] => [[c_name]]
- RemoteExchange[GATHER] => [[c_name]]
- ScanFilterProject[table =
awsdatacatalog:HiveTableHandle{schemaName=tpch100,
tableName=customer, analyzePartitionValues=Optional.empty},
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" =
CAST(("random"() * 1E3) AS int)))] => [[c_name]]
LAYOUT: tpch100.customer
c_custkey := c_custkey:int:0:REGULAR
c_name := c_name:string:1:REGULAR
```
O `filterPredicate` nos resultados mostra que o otimizador mesclou os três predicados originais em dois predicados e alterou a ordem de aplicação deles.
```
filterPredicate = (("c_custkey" = 1500) AND ("c_custkey" = CAST(("random"() * 1E3) AS int)))
```
Como os resultados mostram que o predicado `AND c.c_custkey BETWEEN 1000 AND 2000` não tem efeito, você pode removê-lo sem alterar os resultados da consulta.
Para obter informações sobre os termos usados nos resultados das consultas `EXPLAIN`, veja [Noções básicas dos resultados da instrução EXPLAIN do Athena](athena-explain-statement-understanding.md).
## Exemplos de EXPLAIN ANALYZE
Os exemplos a seguir mostram exemplos de consultas e saídas de `EXPLAIN ANALYZE`.
### Exemplo 1: uso de EXPLAIN ANALYZE para mostrar um plano de consulta e o custo computacional em formato de texto
No exemplo a seguir, `EXPLAIN ANALYZE` mostra o plano de execução e os custos computacionais de uma consulta `SELECT` em logs do CloudFront. O formato é o padrão para saída de texto.
```
EXPLAIN ANALYZE SELECT FROM cloudfront_logs LIMIT 10
```
#### Resultados
```
Fragment 1
CPU: 24.60ms, Input: 10 rows (1.48kB); per task: std.dev.: 0.00, Output: 10 rows (1.48kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer,\
os, browser, browserversion]
Limit[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 10.00 rows, Input std.dev.: 0.00%
LocalExchange[SINGLE] () => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 0.00ns (0.00%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
RemoteSource[2] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 1.00ms (0.03%), Output: 10 rows (1.48kB)
Input avg.: 0.63 rows, Input std.dev.: 387.30%
Fragment 2
CPU: 3.83s, Input: 998 rows (147.21kB); per task: std.dev.: 0.00, Output: 20 rows (2.95kB)
Output layout: [date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]
LimitPartial[10] => [[date, time, location, bytes, requestip, method, host, uri, status, referrer, os,\
browser, browserversion]]
CPU: 5.00ms (0.13%), Output: 20 rows (2.95kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
TableScan[awsdatacatalog:HiveTableHandle{schemaName=default, tableName=cloudfront_logs,\
analyzePartitionValues=Optional.empty},
grouped = false] => [[date, time, location, bytes, requestip, method, host, uri, st
CPU: 3.82s (99.82%), Output: 998 rows (147.21kB)
Input avg.: 166.33 rows, Input std.dev.: 141.42%
LAYOUT: default.cloudfront_logs
date := date:date:0:REGULAR
referrer := referrer:string:9:REGULAR
os := os:string:10:REGULAR
method := method:string:5:REGULAR
bytes := bytes:int:3:REGULAR
browser := browser:string:11:REGULAR
host := host:string:6:REGULAR
requestip := requestip:string:4:REGULAR
location := location:string:2:REGULAR
time := time:string:1:REGULAR
uri := uri:string:7:REGULAR
browserversion := browserversion:string:12:REGULAR
status := status:int:8:REGULAR
```
### Exemplo 2: uso de EXPLAIN ANALYZE para mostrar um plano de consulta em formato JSON
O exemplo a seguir mostra o plano de execução e os custos computacionais de uma consulta `SELECT` em logs do CloudFront. O exemplo especifica JSON como formato de saída.
```
EXPLAIN ANALYZE (FORMAT JSON) SELECT * FROM cloudfront_logs LIMIT 10
```
#### Resultados
```
{
"fragments": [{
"id": "1",
"stageStats": {
"totalCpuTime": "3.31ms",
"inputRows": "10 rows",
"inputDataSize": "1514B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host,\
uri, status, referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "Limit",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 10.0,
"nodeInputRowsStdDev": 0.0
}]
},
"children": [{
"name": "LocalExchange",
"identifier": "[SINGLE] ()",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": [{
"name": "RemoteSource",
"identifier": "[2]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host",\
"uri", "status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 0.625,
"nodeInputRowsStdDev": 387.2983346207417
}]
},
"children": []
}]
}]
}]
}
}, {
"id": "2",
"stageStats": {
"totalCpuTime": "1.62s",
"inputRows": "500 rows",
"inputDataSize": "75564B",
"stdDevInputRows": "0.00",
"outputRows": "10 rows",
"outputDataSize": "1514B"
},
"outputLayout": "date, time, location, bytes, requestip, method, host, uri, status,\
referrer, os, browser, browserversion",
"logicalPlan": {
"1": [{
"name": "LimitPartial",
"identifier": "[10]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "",
"distributedNodeStats": {
"nodeCpuTime": "0.00ns",
"nodeOutputRows": 10,
"nodeOutputDataSize": "1514B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": [{
"name": "TableScan",
"identifier": "[awsdatacatalog:HiveTableHandle{schemaName=default,\
tableName=cloudfront_logs, analyzePartitionValues=Optional.empty},\
grouped = false]",
"outputs": ["date", "time", "location", "bytes", "requestip", "method", "host", "uri",\
"status", "referrer", "os", "browser", "browserversion"],
"details": "LAYOUT: default.cloudfront_logs\ndate := date:date:0:REGULAR\nreferrer :=\
referrer: string:9:REGULAR\nos := os:string:10:REGULAR\nmethod := method:string:5:\
REGULAR\nbytes := bytes:int:3:REGULAR\nbrowser := browser:string:11:REGULAR\nhost :=\
host:string:6:REGULAR\nrequestip := requestip:string:4:REGULAR\nlocation :=\
location:string:2:REGULAR\ntime := time:string:1: REGULAR\nuri := uri:string:7:\
REGULAR\nbrowserversion := browserversion:string:12:REGULAR\nstatus :=\
status:int:8:REGULAR\n",
"distributedNodeStats": {
"nodeCpuTime": "1.62s",
"nodeOutputRows": 500,
"nodeOutputDataSize": "75564B",
"operatorInputRowsStats": [{
"nodeInputRows": 83.33333333333333,
"nodeInputRowsStdDev": 223.60679774997897
}]
},
"children": []
}]
}]
}
}]
}
```
## Recursos adicionais
Para obter mais informações, consulte os recursos a seguir.
+ [Noções básicas dos resultados da instrução EXPLAIN do Athena](athena-explain-statement-understanding.md)
+ [Visualização de planos de execução para consultas SQL](query-plans.md)
+ [Visualizar estatísticas e detalhes de execução para consultas concluídas](query-stats.md)
+ Documentação Trino [https://trino.io/docs/current/sql/explain.html](https://trino.io/docs/current/sql/explain.html)
+ Documentação Trino [https://trino.io/docs/current/sql/explain-analyze.html](https://trino.io/docs/current/sql/explain-analyze.html)
+ [Otimize o desempenho de consultas federadas usando EXPLAIN e EXPLAIN ANALYZE no Amazon Athena](https://aws.amazon.com/blogs/big-data/optimize-federated-query-performance-using-explain-and-explain-analyze-in-amazon-athena/) no *Blog de Big Data da AWS*.
[](http://www.youtube.com/watch?v=7JUyTqglmNU)